Background
Web scraping can be one of the easiest ways of fetching data from websites that don’t have an API or give direct access to their data. This tutorial will cover how to scrape the names, years, ratings, and synopsis of the top 100 adventure movies on IMDb.
Installing Packages
For this tutorial, I’ll be using two packages: rvest and dplyr. Make sure you install them and load them in.
install.packages("rvest")
install.packages("dplyr")
library(rvest)
library(dplyr)
The webpage
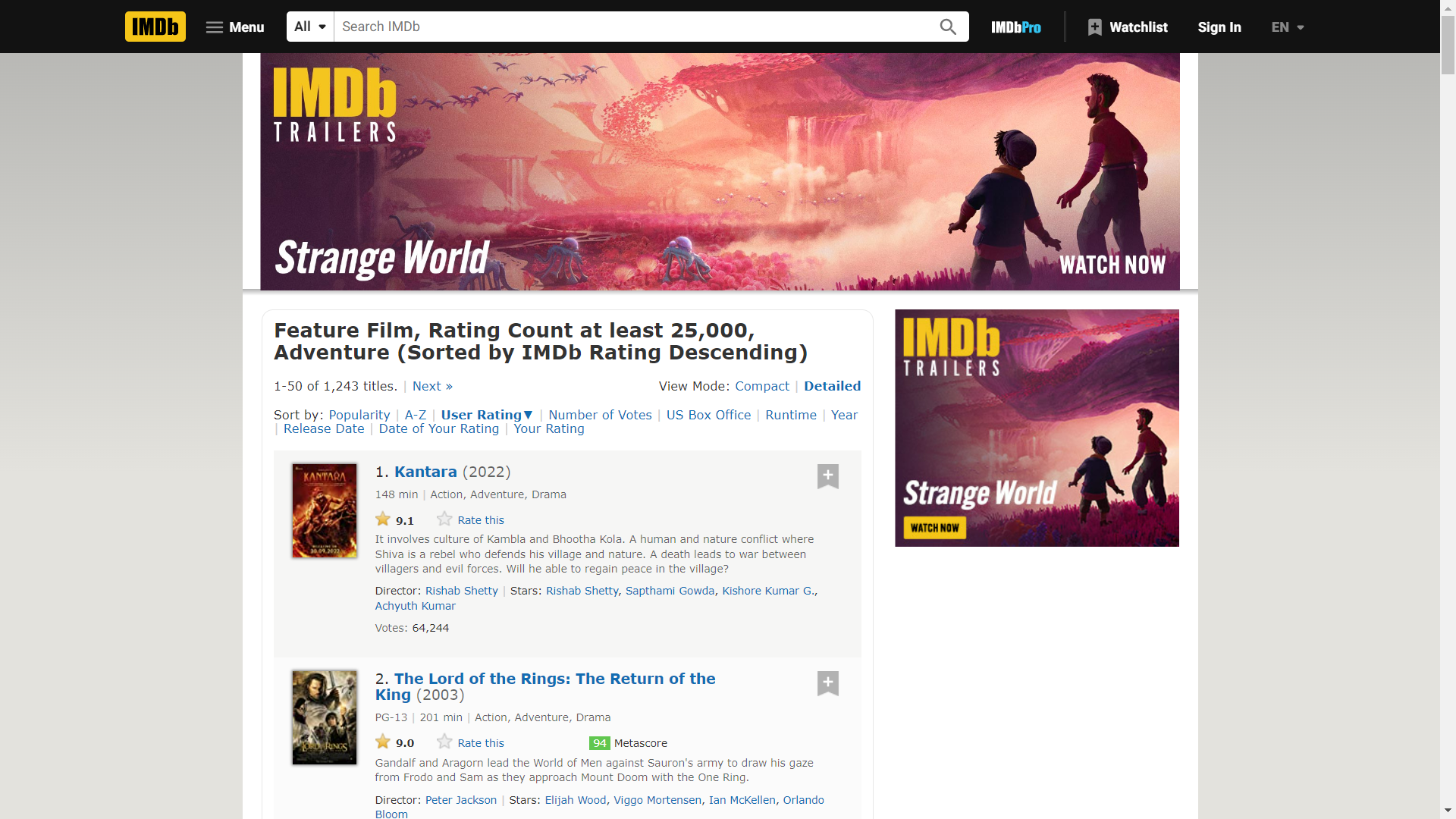
Scraping the data
We can now read in the web page as html
link = "https://www.imdb.com/search/title/?title_type=feature&num_votes=25000,&genres=adventure&sort=user_rating,desc"
page = read_html(link)
Next, we manually scrape each attribute for all the movies at once and convert them to text.
name = page %>% html_nodes(".lister-item-header a") %>% html_text()
year = page %>% html_nodes(".text-muted.unbold") %>% html_text()
rating = page %>% html_nodes(".ratings-imdb-rating strong") %>% html_text()
synopsis = page %>% html_nodes(".ratings-bar+ .text-muted") %>% html_text()
movies = data.frame(name, year, rating, synopsis, stringsAsFactors = FALSE)
Writing to a .csv
Lastly, if we want to save the output, we can write the data to a csv
write.csv(movies, "movies.csv")